Este post mostra como capturar mudanças de dados (CDC) a partir do Postgres e publicá-las no Kafka usando o Debezium como ferramenta de CDC.
Este artigo foi publicado originalmente no Medium.
O desafio
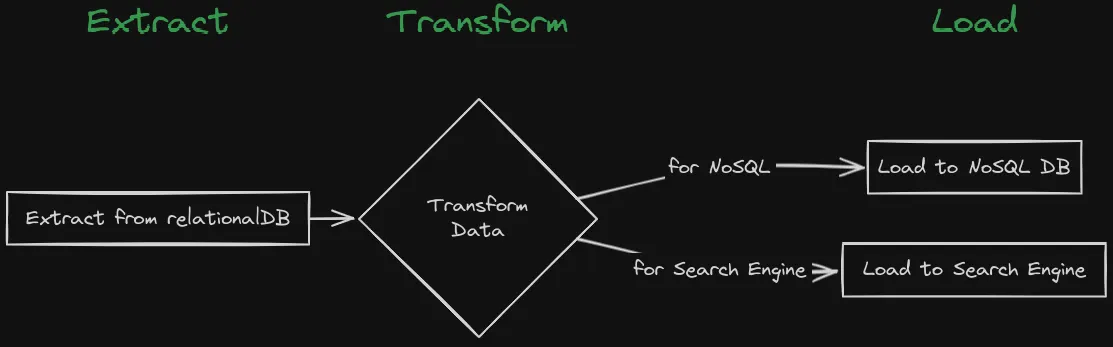
Em grandes empresas, os dados ficam em várias bases. Já vi muitas vezes código que grava os mesmos dados em vários bancos, assim:
relational_db.save(data)
nosql_db.save(data)
search_engine.save(data)Essa abordagem traz desafios grandes:
- Consistência: como manter consistência entre essas bases? E se uma delas falhar? E se a ordem dos dados importar?
- Escalabilidade: como escalar quando o desempenho depende do banco mais lento?
- Complexidade: o código fica difícil de manter - muitos pontos na aplicação e outros microserviços fazendo o mesmo.
O caminho tradicional para aproximar consistência entre bases é o processo ETL (Extract, Transform, Load). O ETL é orientado a lotes: extrai da origem, transforma e carrega no destino. Limitações: não dá sincronização em tempo real, é complexo e caro.
Change Data Capture (CDC)
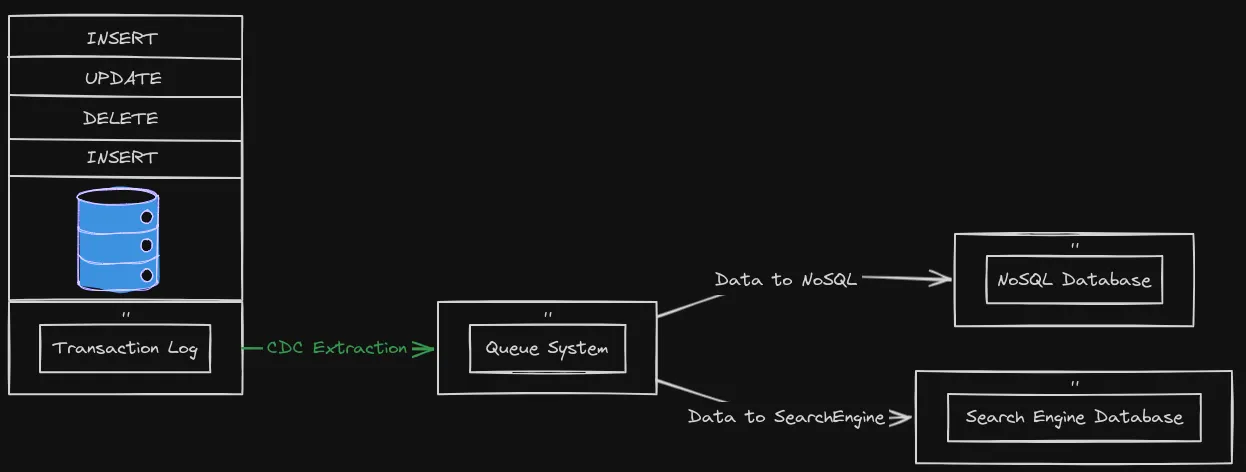
Change Data Capture (CDC) é um termo mais antigo para sistemas que monitorizam e capturam alterações nos dados para que outro software possa reagir. Data warehouses muitas vezes tinham CDC integrado, porque precisam de estar atualizados quando os dados mudam nos OLTP de origem.
Usar o Debezium como ferramenta de CDC
O Debezium é um conjunto de serviços distribuídos que captura alterações ao nível da linha nas suas bases para que as aplicações as vejam e respondam. O Debezium regista no log de transações todas as alterações confirmadas em cada tabela. Cada aplicação lê os logs que lhe interessam e vê os eventos na mesma ordem em que ocorreram.
Lista de bases suportadas aqui.
A saída pode ir para Kafka, Amazon Kinesis, Google Cloud Pub/Sub, etc.
Neste post uso o conector Postgres do Debezium via Kafka Connect.
Vamos levantar Zookeeper, Kafka, PostgreSQL e Connect com comandos docker run individuais.
Zookeeper
O Zookeeper é um serviço centralizado para configuração, nomes, sincronização distribuída e serviços de grupo. Arranque o Zookeeper:
docker run - rm \
- name zookeeper \
-p 2181:2181 \
debezium/zookeeper:2.1Kafka
O Kafka é uma plataforma de streaming distribuída, muito usada em pipelines e aplicações em tempo real.
docker run - rm \
- name kafka \
-p 9092:9092 \
- env ZOOKEEPER_CONNECT=zookeeper:2181 \
- link zookeeper \
debezium/kafka:2.1PostgreSQL
Arranque uma instância PostgreSQL:
docker run - rm \
- name postgres \
-p 5432:5432 \
- env POSTGRES_PASSWORD=postgres \
- env POSTGRES_HOST_AUTH_METHOD=trust \
- env POSTGRES_USER=postgres \
postgres:15.2-alpine3.17Altere o wal_level para logical no ficheiro postgresql.conf. O logical decoding do PostgreSQL existe desde a versão 9.4: permite extrair alterações confirmadas no log de transações e processá-las com um plugin de saída.
- Abra um shell bash no contentor PostgreSQL:
docker exec -it postgres bash- Localize o postgresql.conf:
find / -name postgresql.conf- Edite postgresql.conf, descomente wal_level e defina logical:
wal_level = logical- Saia e reinicie o contentor:
docker restart postgresCriar base de dados e tabela
- Abra o psql no contentor:
docker exec -it postgres psql -U postgres- Crie a base, a tabela e insira dados:
CREATE DATABASE inventory;
\c inventory;
CREATE EXTENSION IF NOT EXISTS "uuid-ossp";
CREATE TABLE products (
id UUID PRIMARY KEY DEFAULT uuid_generate_v4(),
name TEXT NOT NULL,
weight FLOAT NOT NULL,
created_at TIMESTAMPTZ NOT NULL DEFAULT now()
);
INSERT INTO
products (name, weight)
VALUES
('scooter', 3.14),
('car battery', 8.1),
('12-pack drill bits', 0.8),
('hammer', 0.75);Debezium Connect
O Debezium Connect captura alterações ao nível da linha usando o Kafka Connect - framework para ligar o Kafka a sistemas externos (bases, KV, índices de pesquisa, ficheiros).
- Inicie o Debezium Connect:
docker run - rm \
- name connect \
-p 8083:8083 \
- env CONFIG_STORAGE_TOPIC=connect_configs \
- env OFFSET_STORAGE_TOPIC=connect_offsets \
- env STATUS_STORAGE_TOPIC=connect_statuses \
- env BOOTSTRAP_SERVERS=kafka:9092 \
- link kafka \
- link postgres \
debezium/connect:2.1- Registe o conector Postgres:
curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors/ -d '{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname": "inventory",
"topic.prefix": "inventory",
"plugin.name": "pgoutput"
}
}'Estado do conector:
curl -H "Accept:application/json" localhost:8083/connectors/inventory-connector/statusResposta típica com o conector a correr:
{"name":"inventory-connector","connector":{"state":"RUNNING","worker_id":"172.17.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.17.0.5:8083"}],"type":"source"}Tópicos criados:
docker exec connect /kafka/bin/kafka-topics.sh - bootstrap-server kafka:9092 - listDeve aparecer o tópico inventory.public.products.
Consuma o tópico:
docker exec connect /kafka/bin/kafka-console-consumer.sh - bootstrap-server kafka:9092 - topic inventory.public.products - from-beginningVê-se dados no tópico - o snapshot inicial da tabela products. Por omissão o conector usa snapshot.mode = initial: faz um snapshot consistente inicial.
Estrutura da mensagem:
{
"schema": {…},
"payload": {…}
}O campo schema descreve a estrutura (Kafka Connect); payload traz os dados.
Detalhe do payload:
{
"schema": {…},
"payload": {
"before": null,
"after": {
"id": "8eb22f16–1763–4023–8b61–6b6bc21b8e8f",
"name": "hammer",
"weight": 0.75,
"created_at": "2024–04–13T17:04:10.581758Z"
},
"source": {
"version": "2.1.4.Final",
"connector": "postgresql",
"name": "inventory",
"ts_ms": 1713056376651,
"snapshot": "last",
"db": "inventory",
"sequence": "[null,\"26842648\"]",
"schema": "public",
"table": "products",
"txId": 741,
"lsn": 26842648,
"xmin": null
},
"op": "r",
"ts_ms": 1713056376796,
"transaction": null
}
}O campo op indica a operação. O valor "r" significa leitura no processo de snapshot.
Atualize a tabela para ver CDC em ação:
docker exec postgres psql -U postgres -d inventory -c "UPDATE products SET weight = 0.5 WHERE name = 'hammer'"O tópico deve mostrar a alteração:
{
"schema": {…},
"payload": {
"before": null,
"after": {
"id": "8eb22f16–1763–4023–8b61–6b6bc21b8e8f",
"name": "hammer",
"weight": 0.5,
"created_at": "2024–04–13T17:04:10.581758Z"
},
"source": {…},
"op": "u",
"ts_ms": 1713059333521,
"transaction": null
}
}Agora op é "u" (update). after tem o estado novo; before pode ser null. Para ver o estado anterior em updates/deletes, configure REPLICA IDENTITY na tabela. Ver também a documentação Debezium.
Com REPLICA IDENTITY FULL na tabela products, o before passa a trazer os dados anteriores em updates e deletes:
docker exec postgres psql -U postgres -d inventory -c "ALTER TABLE products REPLICA IDENTITY FULL"Outro update:
docker exec postgres psql -U postgres -d inventory -c "UPDATE products SET weight = 1.5 WHERE name = 'hammer'"Mensagem esperada:
{
"schema": {…},
"payload": {
"before": {
"id": "8eb22f16–1763–4023–8b61–6b6bc21b8e8f",
"name": "hammer",
"weight": 0.5,
"created_at": "2024–04–13T17:04:10.581758Z"
},
"after": {
"id": "8eb22f16–1763–4023–8b61–6b6bc21b8e8f",
"name": "hammer",
"weight": 1.5,
"created_at": "2024–04–13T17:04:10.581758Z"
},
"source": {…},
"op": "u",
"ts_ms": 1713102044174,
"transaction": null
}
}Conclusão
Neste guia vimos como capturar mudanças no Postgres e publicá-las no Kafka com Debezium - útil para manter sistemas alinhados. O Debezium suporta MySQL, Postgres, MongoDB, entre outros, e vários sinks (Kafka, Kinesis, Pub/Sub, …).
Em produção entram cenários mais exigentes: alta disponibilidade, monitorização, escala, evolução de schema, etc.
Obrigado por ler!