Neste post partilho os meus primeiros passos no mundo do ClickHouse - uma base orientada a colunas pensada para consultas analíticas muito rápidas. Como alguém relativamente novo nesta tecnologia, o objetivo é desmistificar o ClickHouse e dar um guia prático, com Docker, para o pôr a correr.
Nas secções seguintes explico como executar o demo localmente, pontos importantes de configuração e como criar e usar uma tabela simples.
Escrevi e publiquei este artigo originalmente no DevGenius.
O que é o ClickHouse?
O ClickHouse é um sistema de gestão de bases de dados (SGBD) open source, orientado a colunas, desenhado para processamento analítico online (OLAP). Originalmente desenvolvido na Yandex, tornou-se popular pela capacidade de processar milhares de milhões de linhas por segundo em grandes volumes de dados.
Características principais
- Armazenamento colunar: os dados são guardados por coluna, o que melhora compressão e desempenho em cargas analíticas.
- Analytics em tempo real: consultas complexas sobre grandes conjuntos de dados com latência baixa.
- Escalabilidade: horizontal e vertical, de terabytes a petabytes.
- Tolerância a falhas: replicação e processamento distribuído para alta disponibilidade.
- SQL: dialeto SQL próximo do relacional, acessível a quem já conhece SQL.
Mais informação no site oficial do ClickHouse.
Começar: correr o demo localmente
O projeto usa Docker Compose. Há três ficheiros centrais:
docker-compose.yml- serviço ClickHouse, ambiente, portas e volumes.clickhouse/config/users.xml- definições do servidor, incluindo suporte ao tipo JSON.clickhouse/init/init.sql- DDL da tabelaentities.
1. Clonar o repositório
git clone https://github.com/RafaelAdao/cdp-clickhouse.git
cd cdp-clickhouse2. Estrutura do projeto
cdp-clickhouse/
├── clickhouse
│ ├── config
│ │ └── users.xml
│ └── init
│ └── init.sql
├── docker-compose.yml
├── examples.sql
└── README.md3. Trecho do docker-compose.yml
version: '3.8'
services:
clickhouse:
image: clickhouse
container_name: clickhouse
ports:
- "18123:8123"
- "19000:9000"
environment:
- CLICKHOUSE_PASSWORD=changeme
volumes:
- ./clickhouse/config/users.xml:/etc/clickhouse-server/users.xml:ro
- ./clickhouse/init/init.sql:/docker-entrypoint-initdb.d/init.sql:ro
- clickhouse_data:/var/lib/clickhouse
volumes:
clickhouse_data:- Portas: 8123 (HTTP) e 9000 (TCP nativo) expostas na máquina local.
- Ambiente: palavra-passe por omissão
changeme. - Volumes: config e SQL de init montados; dados persistentes em volume Docker.
4. Arrancar o contentor
docker compose upFaz pull da imagem se necessário, inicia o contentor e executa o init.sql, criando a tabela entities na base default.
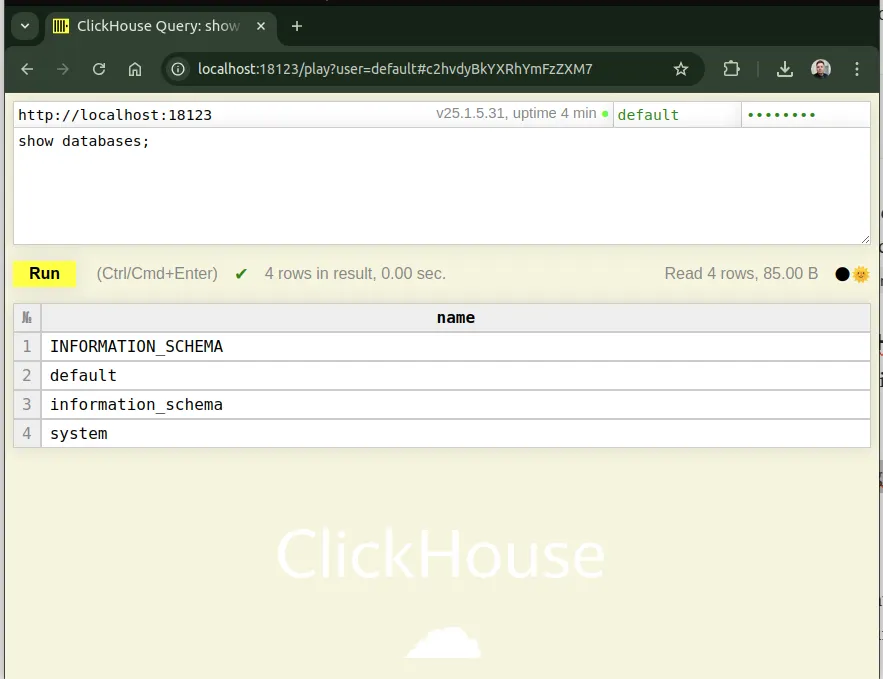
5. Aceder ao ClickHouse
- HTTP / Play UI: http://localhost:18123/play?password=changeme
- Cliente: via Docker:
docker exec -it clickhouse clickhouse-client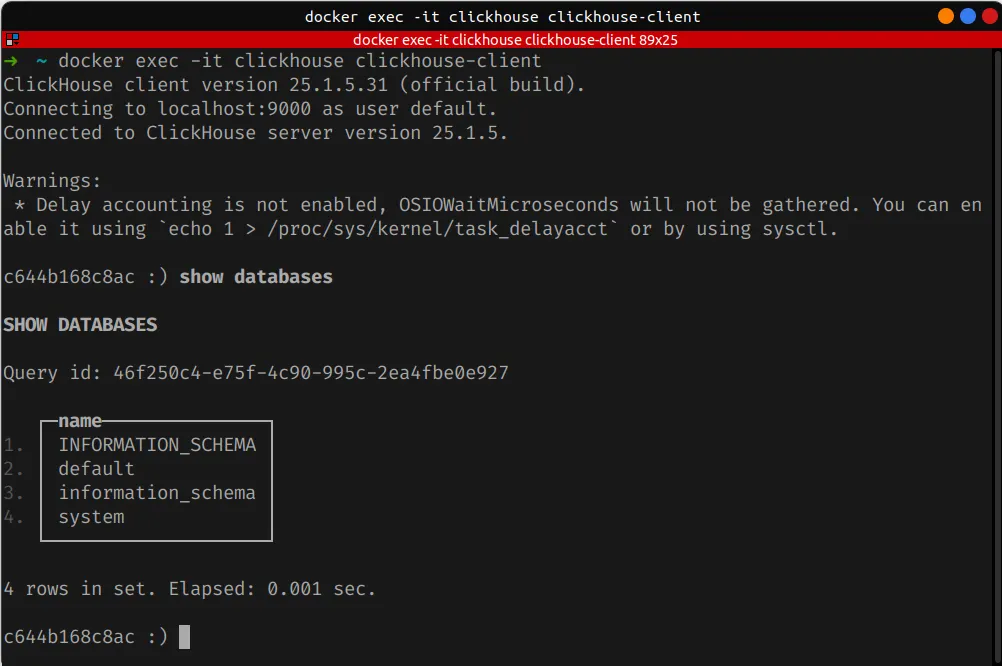
Documentação de interfaces: ClickHouse interfaces.
Configuração: users.xml
O ficheiro clickhouse/config/users.xml configura utilizadores e perfis. No demo, o ponto crítico é <enable_json_type>1</enable_json_type>.
À data do post (2025-02-22), o tipo JSON não vem ativado por omissão. Com esta flag:
- JSON nativo: o ClickHouse trata JSON como tipo próprio, útil para dados semi-estruturados.
- Desempenho: parsing e processamento mais eficientes do que tratar JSON como texto.
- Funções: funções e operadores específicos em SQL.
Trecho relevante:
<yandex>
<users>
<default>
<profile>default</profile>
<networks>
<ip>::/0</ip>
</networks>
</default>
</users>
<profiles>
<default>
<enable_json_type>1</enable_json_type>
</default>
</profiles>
</yandex>Mais detalhes: documentação JSON.
DDL da tabela entities
Definida em clickhouse/init/init.sql:
CREATE TABLE entities
(
tenant_id UInt32,
entity_id String,
properties JSON,
event_time DateTime64(6),
version UInt64 MATERIALIZED toUnixTimestamp64Nano(event_time)
)
ENGINE = ReplacingMergeTree(version)
ORDER BY (tenant_id, entity_id);Modelo multi-tenant com versionamento e deduplicação.
Tipos de dados
tenant_id UInt32: identificador do tenant.entity_id String: ID da entidade dentro do tenant.properties JSON: atributos em JSON.event_time DateTime64(6): instante do evento com precisão de microsegundos.version UInt64 MATERIALIZED toUnixTimestamp64Nano(event_time): coluna materializada - timestamp Unix em nanossegundos derivado deevent_time.
Papel da coluna MATERIALIZED
- Versionamento: valor numérico para ordenar “versões” do mesmo registo.
- Deduplicação: com
ReplacingMergeTree, na fusão mantém-se a linha com maiorversion.
Documentação: materialized columns.
ORDER BY e ReplacingMergeTree
Porquê ORDER BY (tenant_id, entity_id)?
Define a chave primária lógica e a ordem física no disco.
- Leitura eficiente: filtros por
tenant_id/entity_idbeneficiam de indexação por salto de dados. - Menos seeks: dados ordenados ajudam em scans analíticos.
- Multi-tenant: dados do mesmo tenant ficam contíguos.
Otimização de leitura com ORDER BY.
Porquê ENGINE = ReplacingMergeTree(version)?
- Deduplicação: substitui linhas mais antigas pela mais recente segundo a coluna
version. - Fusões em background: processo assíncrono consolida versões.
- Modelo append-only: em vez de
UPDATEclássico, insere-se uma nova versão da linha.
Exemplos práticos
Inserir dados
INSERT INTO entities (tenant_id, entity_id, properties, event_time)
VALUES
(1, 'entity_001', '{"name": "Acme Corporation", "status": "active"}', '2025-02-22 15:30:00.123456'),
(1, 'entity_002', '{"name": "Beta LLC", "status": "inactive", "score": 87}', '2025-02-22 16:00:00.654321'),
(2, 'entity_003', '{"name": "Gamma Inc.", "status": "active", "metrics": {"clicks": 1023, "views": 2048}}', '2025-02-22 17:15:00.000000');Use a secção Aceder ao ClickHouse para executar. O ReplacingMergeTree usará version nas fusões futuras.
Exemplo 1: todas as entidades de um tenant
SELECT tenant_id, entity_id, properties, event_time, version
FROM entities
WHERE tenant_id = 1; ┌─tenant_id─┬─entity_id──┬─properties───────────────────────────────────────────┬─────────────────event_time─┬─────────────version─┐
1. │ 1 │ entity_001 │ {"name":"Acme Corporation","status":"active"} │ 2025-02-22 15:30:00.123456 │ 1740238200123456000 │
2. │ 1 │ entity_002 │ {"name":"Beta LLC","score":"87","status":"inactive"} │ 2025-02-22 16:00:00.654321 │ 1740240000654321000 │
└───────────┴────────────┴──────────────────────────────────────────────────────┴────────────────────────────┴─────────────────────┘Exemplo 2: propriedades JSON
SELECT
entity_id,
properties.name,
properties.status
FROM entities
WHERE properties.status = 'active'; ┌─entity_id──┬─name─────────────┬─status─┐
1. │ entity_001 │ Acme Corporation │ active │
2. │ entity_003 │ Gamma Inc. │ active │
└────────────┴──────────────────┴────────┘Exemplo 3: funções de data
SELECT
tenant_id,
toDate(event_time) AS event_date,
count(*) AS events_count
FROM entities
GROUP BY tenant_id, event_date
ORDER BY tenant_id, event_date; ┌─tenant_id─┬─event_date─┬─events_count─┐
1. │ 1 │ 2025-02-22 │ 2 │
2. │ 2 │ 2025-02-22 │ 1 │
└───────────┴────────────┴──────────────┘Alterar dados na tabela entities
O modelo é append-only: em vez de UPDATE in-place, insere-se uma nova linha com o mesmo tenant_id e entity_id e um event_time mais recente. O motor usa version para decidir qual é a versão vencedora.
Exemplo: atualizar uma entidade
INSERT INTO entities (tenant_id, entity_id, properties, event_time)
VALUES
(1, 'entity_002', '{"name": "Beta LLC", "status": "active", "score": 87}', '2025-02-22 18:00:00.000000');- Novo registo com
event_timeposterior. versionrecalculada automaticamente.- Nas fusões, mantém-se a linha com maior
version.
Duas linhas para entity_002 podem coexistir até à fusão:
SELECT
entity_id,
properties,
event_time,
version
FROM entities
WHERE tenant_id = 1 AND entity_id = 'entity_002'; ┌─entity_id──┬─properties───────────────────────────────────────────┬─────────────────event_time─┬─────────────version─┐
1. │ entity_002 │ {"name":"Beta LLC","score":"87","status":"active"} │ 2025-02-22 18:00:00.000000 │ 1740247200000000000 │
2. │ entity_002 │ {"name":"Beta LLC","score":"87","status":"inactive"} │ 2025-02-22 16:00:00.654321 │ 1740240000654321000 │
└────────────┴──────────────────────────────────────────────────────┴────────────────────────────┴─────────────────────┘O ReplacingMergeTree não atualiza no sítio: insere-se uma nova versão; em background o motor deduplica pela chave primária e pela coluna version. Consultas imediatas podem ainda ver duplicados até a fusão.
Documentação sobre merges e conceitos centrais.
O modificador FINAL força a lógica de deduplicação na consulta (sem esperar só pelas fusões em background):
SELECT
entity_id,
properties,
event_time,
version
FROM entities FINAL
WHERE tenant_id = 1 AND entity_id = 'entity_002'; ┌─entity_id──┬─properties─────────────────────────────────────────┬─────────────────event_time─┬─────────────version─┐
1. │ entity_002 │ {"name":"Beta LLC","score":"87","status":"active"} │ 2025-02-22 18:00:00.000000 │ 1740247200000000000 │
└────────────┴────────────────────────────────────────────────────┴────────────────────────────┴─────────────────────┘FINALaplica a deduplicação do ReplacingMergeTree em tempo de consulta.- Útil quando precisa do estado mais recente antes das fusões.
⚠️ Desempenho: FINAL pode ser caro em tabelas grandes - prefira confiar nas fusões naturais quando possível.
Conclusão
Obrigado por acompanhar este guia. Espero que o ClickHouse pareça um pouco menos intimidante e que tenha vontade de experimentar mais.
O repositório no GitHub pode evoluir em relação ao texto deste post - ajustes, ideias novas e refinamentos. Sugestões e contribuições são bem-vindas.
Continuar a aprender
Recomendo o ClickHouse Learn - cursos interativos e exercícios práticos.