Escrevi e publiquei este artigo originalmente no Medium.
No meu último post, Exploring ClickHouse: A Beginner’s Journey, explorei alguns fundamentos do ClickHouse, fiz uma configuração inicial usando Docker até a criação e manipulação de uma tabela simples chamada entities. Vimos um pouco de ReplacingMergeTree para deduplicação e versionamento, além de exemplos práticos de inserção e consulta de dados.
Neste post a intenção é explorar um exemplo prático usando o ClickHouse para implementar um sistema de segmentação simplificado, semelhante ao que você encontraria em uma Customer Data Platform (CDP). O foco será demonstrar como utilizar funções definidas pelo usuário (UDFs) no ClickHouse para aplicar regras de filtragem complexas e gerar segmentos.
Disclaimer: O código apresentado aqui tem propósito puramente de aprendizado e não é recomendado para uso em ambientes de produção. Para volumes significativos de dados ou casos de uso reais, existem abordagens mais otimizadas e robustas. Este exemplo serve apenas para demonstrar conceitos e possibilidades do ClickHouse de forma simplificada. Além disso, o código utilizado é muito inspirado na apresentação Rebuilding Segmentation with ClickHouse - Patrick McGrath (Klaviyo).
O que é CDP
Uma Customer Data Platform (CDP) é um conceito de tecnologia de marketing projetada para unificar dados de clientes provenientes de diversas fontes, criando perfis únicos e centralizados. Esses perfis permitem modelar comportamentos, analisar dados e compartilhar informações com sistemas que precisam deles, facilitando a personalização de interações e decisões em tempo real. Segundo o material da DataEM, as CDPs são categorizadas por objetivos específicos, como gestão de dados, análise e medição, otimização preditiva, geração de demanda, habilitar interações em tempo real e orquestração de decisões omnichannel.
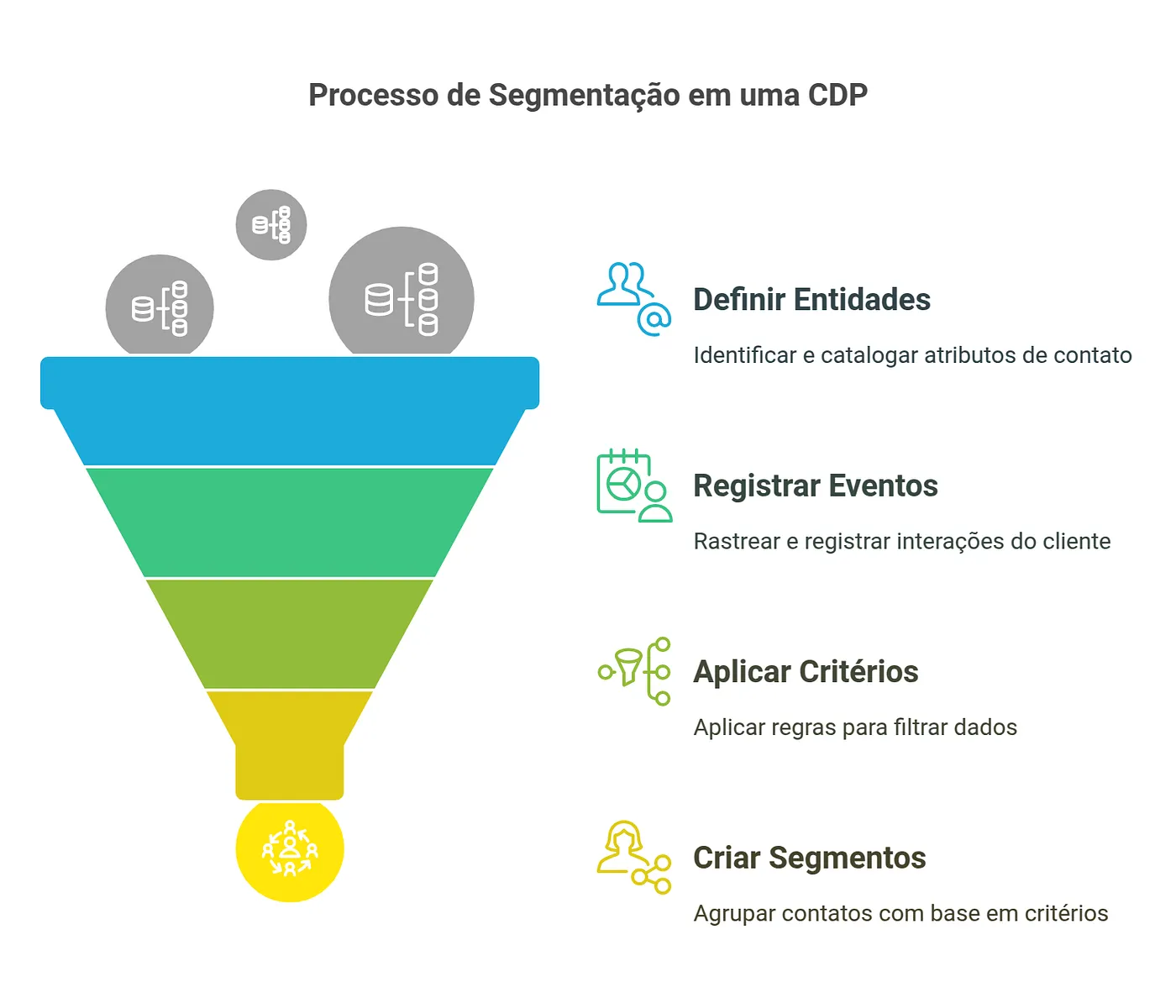
A segmentação é o processo de dividir um grande grupo de entidades (contatos, usuários, clientes, produtos, etc.) em subgrupos menores e mais homogêneos com base em critérios específicos. Vou utilizar a entidade contato para descrever os exemplos.
Em uma CDP, a segmentação permite:
- Agrupar contatos com características semelhantes
- Identificar públicos-alvo para campanhas de marketing
- Personalizar experiências com base no comportamento do contato
- Realizar análises comparativas entre diferentes grupos
Por exemplo, você pode querer criar um segmento de “Clientes Premium” que inclua todos os contatos que gastaram mais de R$ 1.000 nos últimos 3 meses, fizeram pelo menos 5 compras e visitaram seu site mais de 10 vezes.
As regras de uma segmentação básica poderiam ser expressas como:
- Entidades: Representam os contatos com suas propriedades e atributos (nome, email, idade, etc.)
- Eventos: Representam as interações dos contatos com a empresa, como compras, visitas ao site, conversões, etc.
- Critérios: Definem as regras para inclusão em um segmento (exemplo: idade > 30 AND país = “Brasil”)
O processo envolve avaliar cada entidade contra os critérios definidos para cada segmento. Este é um processo que pode ser computacionalmente intensivo em grandes conjuntos de dados, especialmente se houver muitos segmentos e regras complexas.
Escopo a ser explorado
Neste post, vamos focar em:
- Criar funções definidas pelo usuário (UDFs) para aplicar diferentes operadores de comparação
- Definir tabelas para armazenar entidades e critérios de segmentação
- Implementar consultas para aplicar critérios às entidades
- Criar uma view materializada para manter os resultados da segmentação atualizados
O que não será abordado:
- Deduplicação do estado da segmentação
- Gerenciamento de entradas e saídas de segmentos ao longo do tempo
- Otimizações para volumes grandes de dados
- Tratamento de operações OR
- Performance e escala
- Propriedades nested (ex:
address.city)
Um pouco de código
Começando examinando as tabelas necessárias para o exemplo.
A tabela entities armazena informações sobre os contatos. Já conhecemos ela do post anterior.
CREATE TABLE entities
(
tenant_id UInt32,
entity_id String,
properties JSON,
event_time DateTime64(6),
version UInt64 MATERIALIZED toUnixTimestamp64Nano(event_time)
)
ENGINE = ReplacingMergeTree(version)
ORDER BY (tenant_id, entity_id);A tabela criteria define os critérios de segmentação:
CREATE TABLE criteria
(
tenant_id UInt32,
segment_id String,
filters Array(
Tuple(
property_path String, -- Ex: 'city'
operator String, -- Ex: 'eq'
value String, -- Ex: 'São Paulo'
data_type String -- Ex: 'string'
)
),
version UInt32 DEFAULT 1
)
ENGINE = ReplacingMergeTree(version)
ORDER BY (tenant_id, segment_id);Esta tabela armazena critérios de segmentação, ou seja, regras que definem quais entidades (como usuários, produtos, etc.) pertencem a um determinado segmento. Por exemplo, um segmento como “clientes VIP” pode ser definido por critérios como “total de compras acima de R$ 1000” e “status da conta ativo”. Cada linha na tabela representa uma configuração de segmento para um tenant.
A coluna filters é um Array de tuplas, onde:
property_path: nome da propriedade na entidade (ex:city)operator: operador lógico (ex:eq(igual),gt(maior que),contains)value: valor de comparação (ex:São Paulo,1000)data_type: tipo do dado (ex:string,number,boolean), para realizar as conversões e testar corretamente as condições
Exemplo de filtro:
[
('total_purchases', 'gt', '1000', 'number'),
('status', 'eq', 'active', 'string')
]Interpretação: “O contato deve ter mais de 1000 compras E status igual a ‘ativo’”.
Por que a lógica atual é somente AND?
No escopo desse exemplo, todas as condições no array filters devem ser atendidas para uma entidade pertencer ao segmento. Isso significa que a lógica é AND entre os critérios. Não sendo possível definir condições OR ou combinações complexas (ex: (A AND B) OR C). Por exemplo:
[
('age', 'gt', '30', 'number'),
('plan', 'eq', 'premium', 'string')
]Interpretação: “O contato deve ter mais de 30 anos E estar no plano premium”.
Futuramente trarei uma refatoração dessa ideia, com a proposta de:
- Armazenar condições individuais em uma tabela separada.
- Associar cada condição a múltiplos segmentos.
- Permitir combinações flexíveis (
AND,OR,NOT).
Assim poderá haver reutilização de condições entre segmentos, para que uma entidade seja verificada apenas uma vez para dado critério, mesmo o critério estando presente em n segmentações. Mas isso é papo para outro blog post :)
Exemplo de uso prático de critérios
Criação de uma segmentação:
INSERT INTO criteria (tenant_id, segment_id, filters)
VALUES (
1,
'vip-users',
[
('total_purchases', 'gt', '1000', 'number'),
('status', 'eq', 'active', 'string')
]
);- A versão será
1por padrão.
Atualização do segmento:
INSERT INTO criteria (tenant_id, segment_id, filters, version)
VALUES (
1,
'vip-users',
[
('total_purchases', 'gt', '5000', 'number'), -- Critério mais rigoroso
('status', 'eq', 'active', 'string')
],
2 -- Versão incrementada manualmente
);- O ClickHouse substituirá automaticamente a versão
1pela2graças aoReplacingMergeTree.
Consultando os registros:
SELECT *
FROM criteria
FINAL -- Apenas para fins de visualização
WHERE tenant_id = 1 AND segment_id = 'vip-users'; ┌─tenant_id─┬─segment_id─┬─filters────────────────────────────────────────────────────────────────────────────────┬─version─┐
1. │ 1 │ vip-users │ [('total_purchases','gt','5000','number'),('status','eq','active','string')] │ 2 │
└───────────┴────────────┴────────────────────────────────────────────────────────────────────────────────────────┴─────────┘Criando funções UDF
Agora vamos criar funções customizadas para lidar com diferentes tipos de comparações. Estas funções serão responsáveis por calcular a segmentação, definindo se um contato atende um critério de segmentação.
Para comparações de strings:
CREATE FUNCTION compareStrings AS (op, value, target) ->
multiIf(
op = 'eq', value == target,
op = 'neq', value != target,
op = 'contains', position(value, target) > 0,
op = 'starts_with', startsWith(value, target),
false
);Para comparações numéricas:
CREATE FUNCTION compareNumbers AS (op, value, target) ->
multiIf(
op = 'eq', value == target,
op = 'neq', value != target,
op = 'gt', value > target,
op = 'gte', value >= target,
op = 'lt', value < target,
op = 'lte', value <= target,
false
);Para comparações booleanas:
CREATE FUNCTION compareBooleans AS (op, value, target) ->
multiIf(
op = 'eq', value == target,
op = 'neq', value != target,
false
);E finalmente, uma função de nível superior que direciona para a função de comparação apropriada com base no tipo de dados:
CREATE FUNCTION filterMatches AS (type, value, op, target) -> multiIf(
type == 'string',
compareStrings(op, value, target),
type == 'number',
compareNumbers(op, accurateCastOrNull(value, 'Float64'), accurateCastOrNull(target, 'Float64')),
type == 'boolean',
compareBooleans(op, accurateCastOrNull(value, 'Bool'), accurateCastOrNull(target, 'Bool')),
type == 'datetime',
compareNumbers(op, toUnixTimestamp64Nano(accurateCastOrNull(value, 'DateTime64')),
toUnixTimestamp64Nano(accurateCastOrNull(target, 'DateTime64'))),
NULL
);Abaixo seguem alguns exemplos explorando um pouco as funções criadas:
-- Quando a condição é atendida
SELECT filterMatches('string', 'João Silva', 'eq', 'João Silva') AS result;
-- Quando a condição não é atendida
SELECT filterMatches('number', '35', 'lt', '30') AS result;
-- Comparando datas
SELECT
filterMatches(
'datetime',
'2023-01-15 10:30:00',
'gt',
'2023-01-15 10:00:00'
) AS result;
-- Com duas condições
SELECT
filterMatches('string', 'João Silva', 'eq', 'João Silva') AS result1,
filterMatches('number', '35', 'gt', '30') AS result2;
-- OU para N condições
SELECT
arrayAll(
filter -> (
filterMatches(filter.1, filter.2, filter.3, filter.4) = 1
),
[
('string', 'João Silva', 'eq', 'João Silva'),
('number', '35', 'gt', '30')
]
) AS result;-- result da primeira query
┌─result─┐
1. │ 1 │
└────────┘
-- segunda
┌─result─┐
1. │ 0 │
└────────┘
-- datetime
┌─result─┐
1. │ 1 │
└────────┘
-- duas colunas
┌─result1─┬─result2─┐
1. │ 1 │ 1 │
└─────────┴─────────┘
-- arrayAll
┌─result─┐
1. │ 1 │
└────────┘Aplicando os critérios e segmentando os contatos
Agora que temos as funções e tabelas, podemos criar uma consulta que aplica os critérios de segmentação às entidades:
SELECT
e.tenant_id,
c.segment_id,
e.entity_id
FROM entities AS e
INNER JOIN criteria AS c ON e.tenant_id = c.tenant_id
WHERE arrayAll(
filter -> filterMatches(
filter.data_type,
JSONExtractString(e.properties::String, filter.property_path),
filter.operator,
filter.value) = 1,
c.filters
);Esta consulta faz o seguinte:
- Junta as tabelas
entitiesecriteriapelotenant_id - Para cada par entidade-critério, aplica todos os filtros definidos no critério
- A função
arrayAllgarante que todos os filtros sejam satisfeitos - Para cada filtro, é usado
filterMatchespara aplicar a comparação correta com base no tipo de dados - A função
JSONExtractStringextrai valores do campo JSONproperties
Vamos inserir alguns critérios de segmentação e entidades para testar a consulta:
INSERT INTO criteria (tenant_id, segment_id, filters) VALUES
(1, 'high_fit',
[
('industry', 'eq', 'Marketing', 'string'),
('company_size', 'gte', '50', 'number'),
('job_title', 'contains', 'CEO', 'string'),
('budget', 'gte', '10000', 'number')
]
),
(1, 'high_interest',
[
('website_activity', 'gte', '70', 'number'),
('email_engagement', 'gte', '50', 'number'),
('trial_used', 'eq', 'true', 'boolean'),
('last_activity', 'gte', '2025-02-01', 'datetime')
]
);
INSERT INTO
entities (tenant_id, entity_id, properties, event_time)
VALUES
(
1,
'lead_001',
'{"industry": "Marketing", "company_size": 100, "job_title": "CEO", "website_activity": 80, "email_engagement": 60, "trial_used": true, "budget": 15000, "last_activity": "2025-02-15"}',
now()
),
(
1,
'lead_002',
'{"industry": "Retail", "company_size": 30, "job_title": "Marketing Manager", "website_activity": 50, "email_engagement": 30, "trial_used": false, "budget": 5000, "last_activity": "2025-01-20"}',
now()
),
(
1,
'lead_003',
'{"industry": "Marketing", "company_size": 80, "job_title": "CTO", "website_activity": 90, "email_engagement": 80, "trial_used": true, "budget": 20000, "last_activity": "2025-02-10"}',
now()
);Agora ao executar a consulta, teremos:
SELECT
e.tenant_id,
c.segment_id,
e.entity_id
FROM entities AS e
INNER JOIN criteria AS c ON e.tenant_id = c.tenant_id
WHERE arrayAll(
filter -> filterMatches(
filter.data_type,
JSONExtractString(e.properties::String, filter.property_path),
filter.operator,
filter.value) = 1,
c.filters
); ┌─tenant_id─┬─segment_id────┬─entity_id─┐
1. │ 1 │ high_fit │ lead_001 │
2. │ 1 │ high_interest │ lead_001 │
3. │ 1 │ high_interest │ lead_003 │
└───────────┴───────────────┴───────────┘Isso significa que, de acordo com os critérios de segmentação e os dados das entidades inseridas:
lead_001pertence ao segmentohigh_fit.lead_001também pertence ao segmentohigh_interest.lead_003pertence ao segmentohigh_interest.lead_002não pertence a nenhum dos segmentos (high_fitnemhigh_interest).
Segmento high_fit
Os critérios para o segmento high_fit são:
industryigual aMarketing(string)company_sizemaior ou igual a 50 (número)job_titlecontémCEO(string)budgetmaior ou igual a 10000 (número)
Analisando lead_001 para o segmento high_fit:
industry: “Marketing” é igual aMarketing(verdadeiro)company_size: 100 é maior ou igual a 50 (verdadeiro)job_title: “CEO” contémCEO(verdadeiro)budget: 15000 é maior ou igual a 10000 (verdadeiro)
Conclusão: lead_001 atende a todos os critérios do segmento high_fit; portanto, pertence a este segmento.
Analisando lead_002 para o segmento high_fit:
industry: “Retail” não é igual aMarketing(falso)
Conclusão: lead_002 não atende a todos os critérios do segmento high_fit (falhou já no primeiro critério); portanto, não pertence a este segmento.
O restante dos cálculos segue a mesma lógica.
Criando uma materialized view
A ideia da utilização de uma materialized view é imaginar o seguinte cenário:
- Tabela
entities: contém milhões de registros de usuários, cada um com propriedades dinâmicas armazenadas em JSON. - Tabela
criteria: define centenas de segmentos com múltiplas regras de filtragem. - Precisamos responder rapidamente à pergunta: “Quais contatos pertencem a um segmento específico?”
Se dependêssemos apenas de queries tradicionais, cada consulta teria que:
- Escanear a tabela
entities. - Aplicar as regras de filtragem definidas em
criteria. - Reprocessar toda a lógica de comparação para cada contato.
Isso seria extremamente ineficiente, especialmente em cenários de alta cardinalidade. É aqui que a materialized view entra em cena.
Uma materialized view é uma estrutura de banco de dados que armazena os resultados de uma consulta pré-computada e persistida em disco, permitindo acesso rápido aos dados sem a necessidade de reprocessar a lógica da consulta toda vez que ela é executada. Diferentemente de uma visão padrão (view), que apenas define a consulta e executa-a dinamicamente, a materialized view armazena fisicamente os dados resultantes. Consulte a documentação oficial do ClickHouse sobre incremental materialized view.
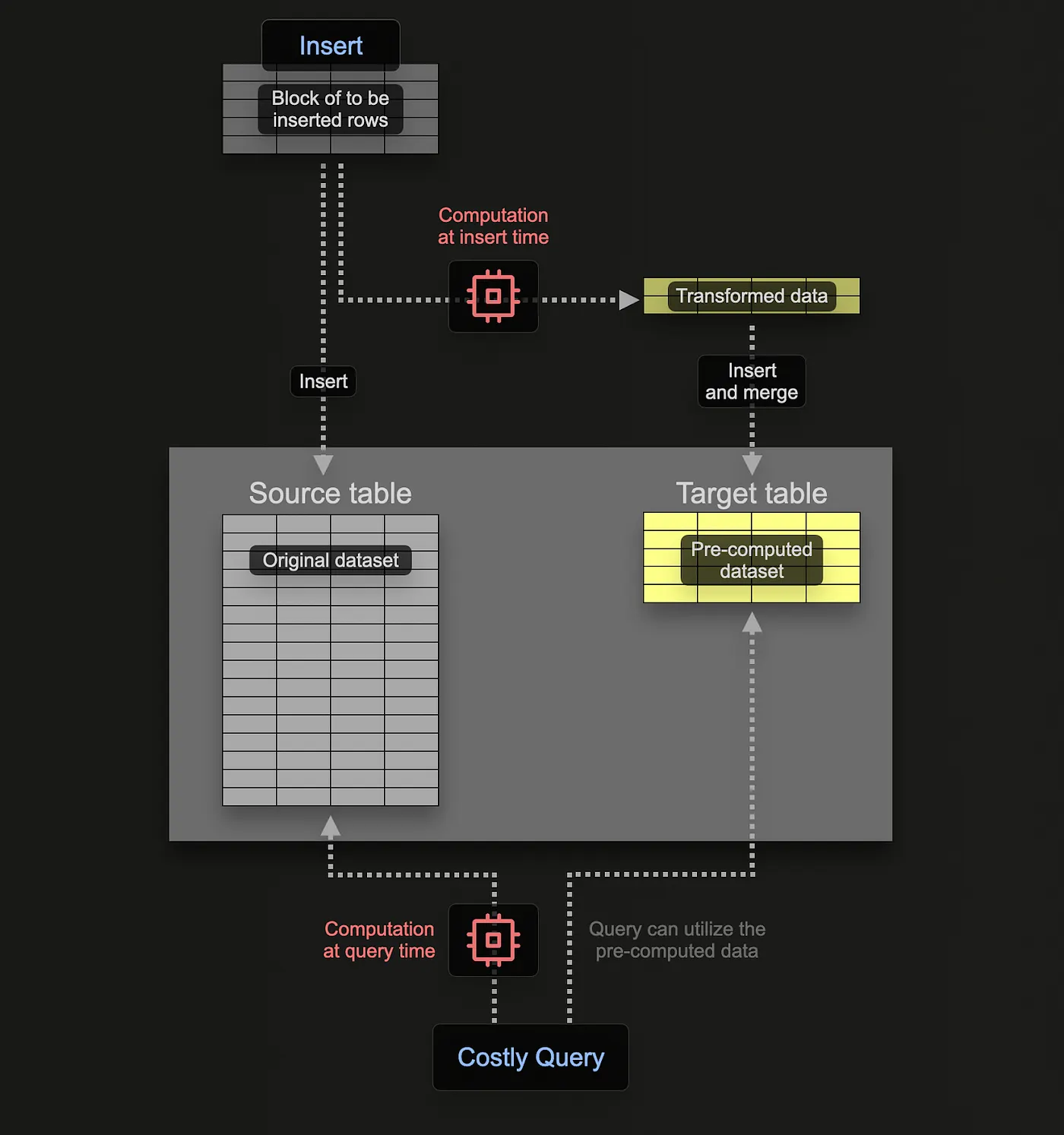
Para manter os resultados de segmentação atualizados automaticamente, vamos à criação da materialized view. O objetivo é materializar os resultados da segmentação no tempo de escrita de contatos no banco de dados.
A materialized view segment_membership_mv será criada com base nas tabelas entities e criteria. Ela armazenará, além da tenant_id:
segment_id: identificador da segmentaçãofilters: critérios da segmentaçãoentity_id: identificador da entidade (contato)properties: propriedades do contato
No repositório, a tabela de destino segment_membership é definida antes da view; ajuste o ENGINE e o ORDER BY conforme o seu caso.
CREATE MATERIALIZED VIEW segment_membership_mv
TO segment_membership
AS SELECT
e.tenant_id,
c.segment_id,
c.filters,
e.entity_id,
e.properties
FROM entities AS e
INNER JOIN criteria AS c ON e.tenant_id = c.tenant_id
WHERE arrayAll(
filter -> filterMatches(
filter.data_type,
JSONExtractString(e.properties::String, filter.property_path),
filter.operator,
filter.value) = 1,
c.filters
);Notar que o filtro WHERE utilizado na consulta anterior foi reaproveitado.
Esta view materializada executa a consulta de segmentação sempre que há mudanças na tabela base (entities) e armazena os resultados na tabela segment_membership. Funciona como se fosse um trigger, e executa somente para os novos dados que chegam na tabela base, evitando a necessidade de executar a consulta para todos os registros.
Exemplo de uso
Vamos criar uma segmentação de usuários premium de São Paulo; para isso começamos inserindo os critérios da segmentação.
INSERT INTO criteria (tenant_id, segment_id, filters) VALUES
(1,'premium_sp',
[
('is_premium', 'eq', 'true', 'boolean'),
('city', 'eq', 'São Paulo', 'string')
]
);E agora vamos inserir os contatos.
INSERT INTO entities (tenant_id, entity_id, properties, event_time) VALUES
(1, 'user1', '{"is_premium": true, "city": "São Paulo"}', now()),
(1, 'user2', '{"is_premium": false, "city": "Rio de Janeiro"}', now());Ao consultar a tabela segment_membership, é possível ver que o user1 atende ao critério premium_sp. Esse dado foi computado no momento da inserção dos contatos.
SELECT * FROM segment_membership; ┌─tenant_id─┬─segment_id─┬─filters───────────────────────────────────────────────────────────────────┬─entity_id─┬─properties─────────────────────────────┐
1. │ 1 │ premium_sp │ [('is_premium','eq','true','boolean'),('city','eq','São Paulo','string')] │ user1 │ {"city":"São Paulo","is_premium":true} │
└───────────┴────────────┴───────────────────────────────────────────────────────────────────────────┴───────────┴────────────────────────────────────────┘Conclusão
Neste post, exploramos como testar funções no ClickHouse utilizando um exemplo prático de segmentação. Recapitulamos os conceitos abordados no post anterior, explicamos o que é segmentação em uma CDP e introduzimos vagamente o que se espera de como uma segmentação funcione. Abordamos o escopo do exemplo focando na criação de UDFs, aplicação de queries e criação de uma materialized view.
Lembre-se: os exemplos aqui apresentados são puramente educacionais e devem ser refinados para utilização em ambientes de produção.
À medida que continuo aprendendo e melhorando meu entendimento, o repositório do GitHub pode evoluir e parecer um pouco diferente deste post do blog. Vou refinar a configuração, experimentar novas ideias e fazer ajustes com base no que descobrir ao longo do caminho. Sinta-se à vontade para conferir, contribuir ou compartilhar seus próprios insights!